---
title: "A Harness for Every Run"
description: "A reflection on Anthropic's dynamic workflows post, from someone building a browser agent on the same idea."
tldr: "Anthropic named the three ways long agent runs fail: agentic laziness, self-preferential bias, goal drift. Building Wire, a browser agent on Steel, I'd fought all three without the words. What the post nails, and three things the browser substrate forces you to add."
date: 2026-06-03
tags: [HUMAN, OPINION, AI, AGENTS]
draft: false
author: "Nikola Balić"
topics: [Dynamic workflows, agent orchestration, browser agents, agent failure modes, prompt injection, verification, multi-agent systems]
entities: [Anthropic, Claude Code, Wire, Steel, Opus 4.8, trq212]
answers_questions:
- What are the three ways long single-context agent runs fail?
- How do dynamic workflows change when the substrate is a real browser instead of a codebase?
- Why should fan-out be gated on evidence instead of a fixed number of agents?
- When is quarantine a security primitive rather than a triage convenience?
---
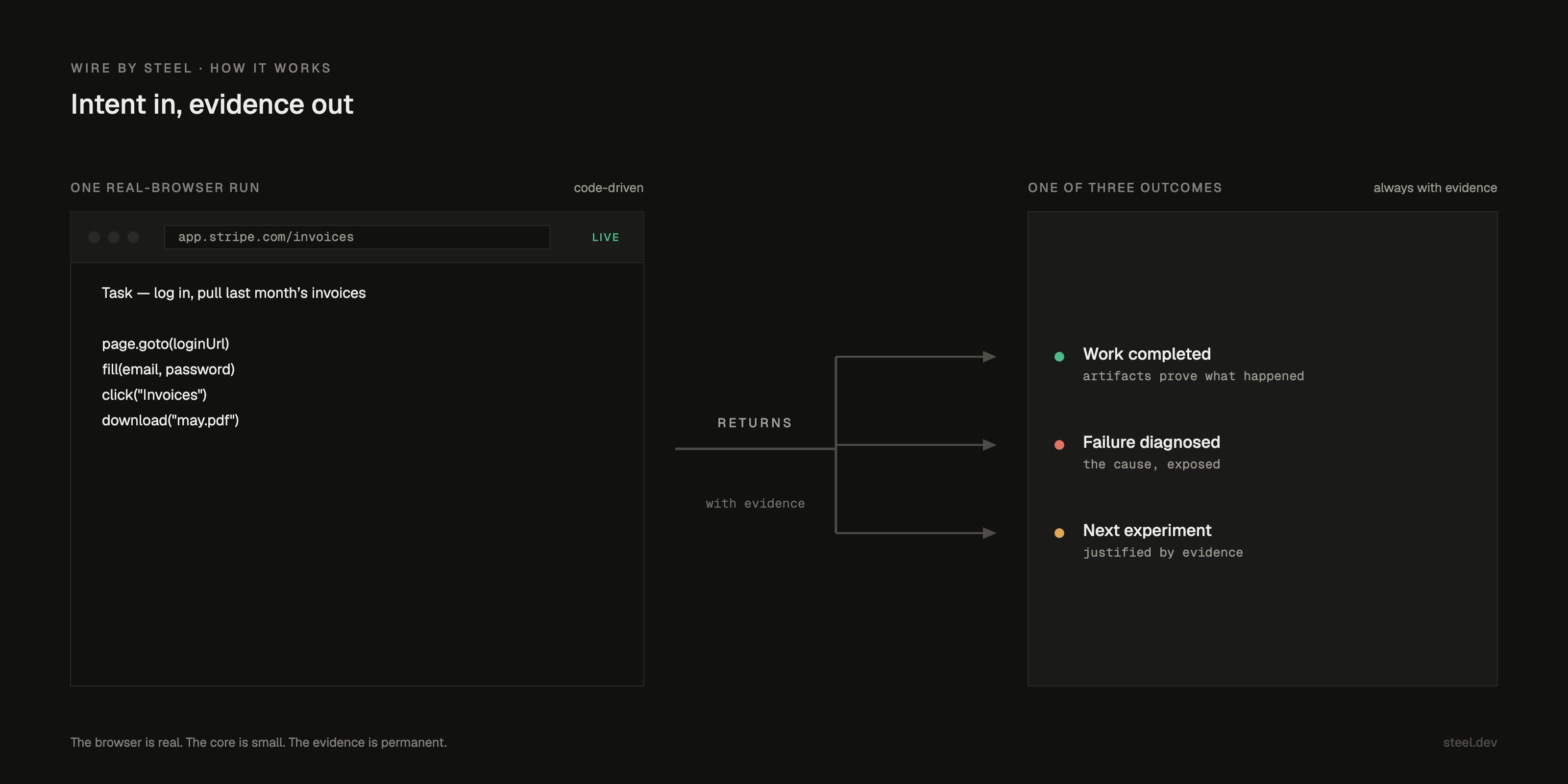
The web is not an API. It's state, latency, auth, pixels, JS, downloads, dialogs, blockers, and consequences. We've been building an agent that works there: Wire, a small runtime that drives real Chrome through [Steel](https://steel.dev) and hands back evidence, not vibes.
Intent in, evidence out. One real-browser run returns one of three outcomes, always with evidence.
So Anthropic shipped [dynamic workflows](https://x.com/trq212/status/2061907337154367865). Mostly, it validated two months of work. They got to "orchestrate separate Claudes with their own context windows" from the coding side, with a clean framework and the names for why. I'd been feeling toward the same thing from the browser side, with far less clarity. The post is what gave me the words.
Here's what it nails, what shipping against it this week cost us, and three things I'd add from a place where the substrate bites back.
## The three failure modes are real, and now they have names
The sharpest thing in the post isn't the API. It's the taxonomy. Long single-context runs fail in three specific ways:
- **Agentic laziness** — the agent declares victory after partial progress. Twenty of fifty review items, then "done."
- **Self-preferential bias** — ask it to grade its own work against a rubric and it grades on a curve it set.
- **Goal drift** — enough turns plus one compaction and the "don't do X" constraint quietly evaporates.
I didn't have these names. I had the bugs. Our commit log from the last two weeks is a running fight with the first two:
```
fix(agent): re-prompt for real extraction instead of finishing on a page dump
fix(agent): wait for content before scraping; never surface a nav ack as the result
```
That's agentic laziness, patched one symptom at a time. "Finishing on a page dump" is the browser version of stopping at item twenty. And our benchmark harness grades every agent with a separate, blind LLM judge for one reason: we already knew the agent couldn't be trusted to grade its own run. We conceded self-preferential bias before we had the word for it.
Naming a failure mode is most of the cure. Once you can say "that's goal drift," you stop arguing with the prompt and start arguing with the architecture.
## We converged on the same patterns
Some of this was already in Wire's spec: hypotheses, run branching, ablations, counterexample search, compare views.
Wire also has a manifesto, a one-page list of beliefs I wrote down before most of the code existed. That's how I've ended up working with agents: get the strong opinions out of my head and into plain language first, so the agent (and future me) has something to be held to. One of those beliefs: make uncertainty explicit; branch; compare; reject hypotheses; find counterexamples.
Line up the post's six patterns against what Wire already had and the overlap is almost embarrassing. Two substrates, the same six shapes. We didn't copy the patterns; we converged on them.
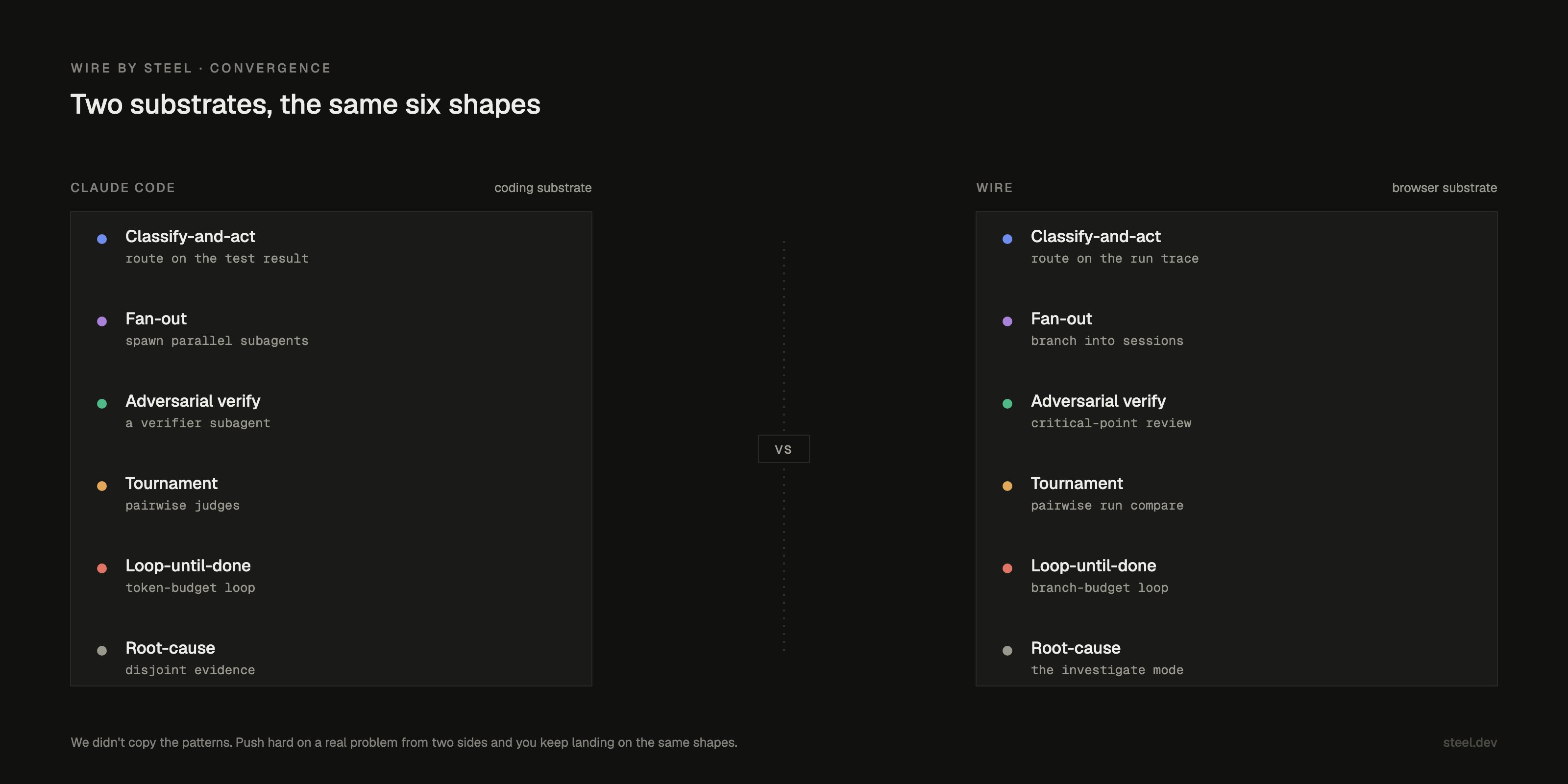
Convergence beats agreement, and there's a wonderful magic to it. Push hard enough on a real problem, from enough different angles, and you keep landing on the same shapes. Eyes evolved independently dozens of times because eyes work. Good software designs stop being invented and start getting discovered.
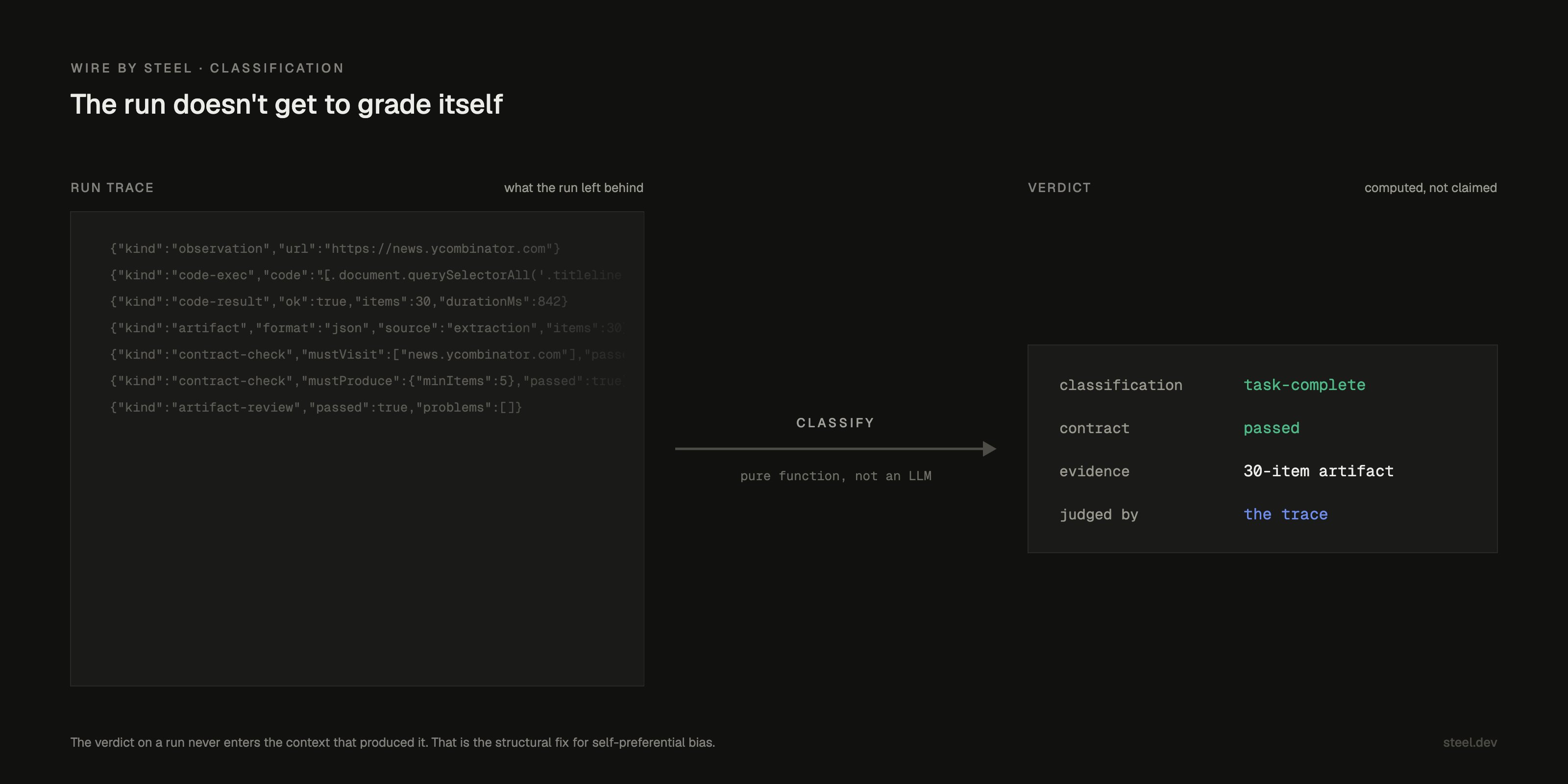
One thing I think we got right early, and it generalizes. Our run classifier is a pure function over trace evidence: code-result counts, artifact presence, contract checks. It's not an LLM grading itself. The verdict on "did this run succeed" never enters the context that produced the run.
That's the structural fix for self-preferential bias: don't make the worker the judge. Compute the verdict from what it left behind. Evidence, not opinion.
Same instinct the post reaches for with separate verifier agents, one layer down. The run doesn't get to grade itself; the verdict is computed from the trace, not claimed by the agent.
## Three things I'd add from the browser
The post is written for an agent whose tools are mostly cheap and mostly safe: read a file, run a test, grep a log. A browser agent lives somewhere rougher. Three of these ideas change character when you drag them into our world.
### 1. Fan-out isn't free, so gate it on evidence, not on N
In Claude Code, another subagent costs tokens and a worktree. In Wire, every subagent is a real browser session: a Steel VM, dollars a minute, a fresh or warmed auth profile, another roll of the dice against anti-bot. Parallelism has a blast radius measured in money and identity, not just context.
We can run it wide — [Wire driving dozens of concurrent sessions at once](https://x.com/steeldotdev/status/2052676916109574545), the fan-out made literal: a prompt fanning out across many agents, many browsers, many screens, each making its own plan against the same task while you watch and step in.
But "can" isn't "should."
The post asks, politely, "does it really need more compute?" For us that's not rhetorical, it's the budget line. So our branching rule isn't "run five and synthesize." We branch only when one more run would actually move uncertainty: last run was ambiguous, a failure has multiple plausible causes, confidence is genuinely low.
The manifesto already said it in plain English: when one more run can answer a real question, branch. The post hands us the mechanism; the substrate enforces the discipline. Anyone running workflows against expensive or stateful tools should steal the same gate. The question is never how many agents, but what the next agent resolves that the last one couldn't.
### 2. Quarantine is a security primitive, not a triage nicety
The post frames quarantine as a triage move: let the agents reading untrusted public content use read-only tools, and let a separate privileged actor act on their structured summaries. It's pitched as a nice-to-have.
For a browser agent it's load-bearing. Reading adversarial untrusted content is the entire job. Every page is potential prompt injection; a site can try to steer the agent the second it loads. If the context that ingests a hostile page also holds the "submit payment" or "delete account" button, you've wired the attack surface straight to the trigger.
So we're pulling quarantine up the stack, from triage trick to default posture. A reader context that ingests page content can't take privileged actions; it can only emit a structured summary. A separate actor context acts on the summary, never the raw page.
For an agent that reads the open web, that split isn't optional hardening. It's the line between operating the web and being operated by it.
### 3. Let the model write the harness, but keep the harness inspectable
The boldest claim in the post is that Opus 4.8 is now smart enough to write a custom harness per task, on the fly. I believe it. I also refuse, for now, to let that harness be disposable.
The manifesto's rule: store the map, not the diary. A workflow that runs once and vanishes is a diary — no durable, inspectable record of how the problem got decomposed. Our compromise, and our proposal: let the model propose the experiment matrix, then promote the good ones into saved, inspectable artifacts, the same skill-promotion path we already use for durable site knowledge. The post points the same way when it ships a workflow file inside a skill folder next to `SKILL.md`. A proven harness for a recurring task should outlive the run that found it, in a file a human can read and diff.
One smaller thing in the same spirit. The post's "one verifier per rule" diagram has a step I missed at first: a skeptic that re-reads each flagged violation and asks "real, or false positive?" before anything's confirmed. Verifier-per-rule without a skeptic over-fires; it'll fail honest runs on a technicality. If you default verification on, like we just did, you owe it a skeptic. Adversarial verification needs its own adversary.
## The fine line
None of this makes the browser easy. It makes failure useful, which is the only thing we've ever promised. Dynamic workflows aren't the win. They're a means. The win is what it always was: a run is complete not because the agent says so, but because the evidence proves what happened. And when it didn't happen, the evidence says why, and what to try next.
The post gave that instinct a vocabulary and an API. We gave it a substrate that doesn't forgive sloppiness. Put together, the position is simple:
> Make the browser real. Make the core small. Make actions inspectable. Make failures useful. Make lessons durable.
And when a task is parallel, adversarial, or long — when one more run can answer a real question — don't make one context carry all of it.
Branch. Compare. Reject. Keep the receipts.
---
*Wire is a zero-weight browser agent built on [Steel](https://steel.dev). The repo is still private — we're hoping to open it up soon. The classifier, branching, and verification work above is real; the experiment-divergence and default-verification changes shipped internally this week.*