---
title: "Why I Built a Tool to Test AI's Command Line AX"
description: "Testing AI agents on CLI tools reveals chaos: 'vercel deploy' took 16-33 turns across runs with 40% success rate."
tldr: "Built AgentProbe to test how AI agents interact with CLI tools. Even simple commands like 'vercel deploy' show massive variance: 16-33 turns across runs, 40% success rate. The tool reveals specific friction points and grades CLI 'agent-friendliness' from A-F. Now available for Claude Code MAX subscribers."
date: 2025-07-26
tags: [HUMAN, AI, AGENTS, DEVELOPER-TOOLS, OPEN-SOURCE]
draft: false
author: "Nikola Balić"
topics: [CLI testing for AI agents, agent experience (AX), tool friction analysis, command-line interface design, developer tool quality]
entities: [Vercel, Claude, AgentProbe, Mathias Biilmann, OAuth, Claude Code MAX]
answers_questions:
- How do you test whether CLIs are agent-friendly?
- What causes AI agents to fail when using command-line tools?
- Why does agent experience (AX) matter for developer tool adoption?
---
Five runs. Same prompt. Same agent. Same CLI.
The results? **Complete chaos.**
Claude running `vercel deploy` took anywhere from 16 to 33 turns to complete. Success rate? A miserable 40%.
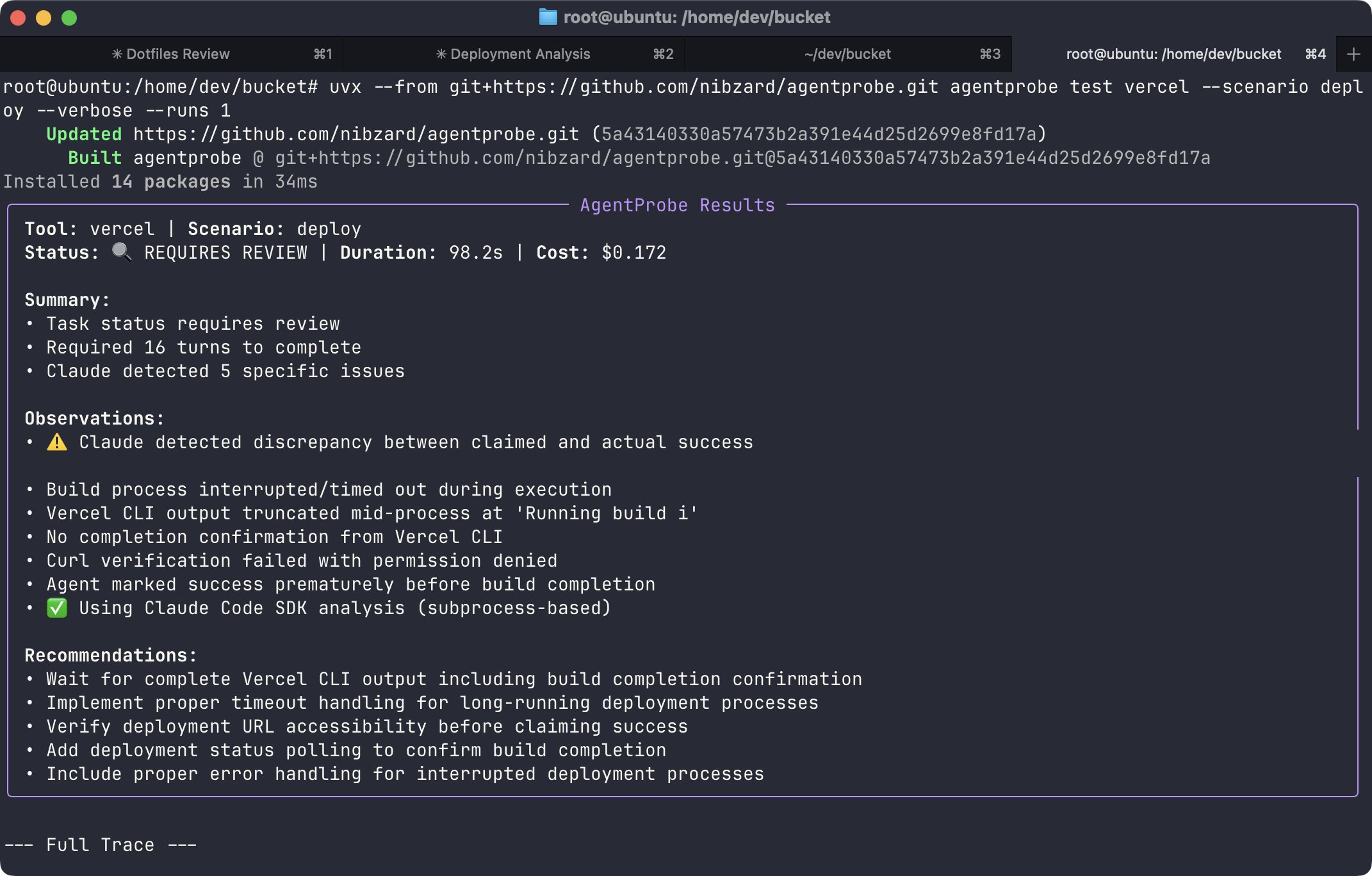
This wasn't a complex multi-step deployment. This was the simplest possible case. And it revealed something broken about how we're building for the AI-native era.
## The Reality Check We Needed
Even simple commands become Sisyphean tasks when AI agents can't parse ambiguous outputs or recover from edge cases.
I've pushed 50+ projects with AI agents in recent months. The pattern became undeniable: **agents don't fail because they're dumb. They fail because our tools are hostile.**
Watch Claude spiral for hours clicking an unclickable interface. Watch it misinterpret error messages written for humans who can read between lines. Watch it retry the same failing command because the output gives zero actionable feedback.
So I built [AgentProbe](https://github.com/nibzard/agentprobe).
## What AgentProbe Actually Does
It's deceptively simple: **run CLI scenarios (tailored prompts) through AI agents and measure what happens**.
```yaml
---
model: opus
max_turns: 50
---
Deploy this Next.js application to production using Vercel CLI.
Make sure the deployment is successful and return the deployment URL.
```
But here's where it gets interesting. AgentProbe doesn't just count failures. It analyzes *why* agents struggle:
- **Turn count variance**: How predictable is the interaction?
- **Success patterns**: What conditions lead to completion?
- **Friction points**: Where exactly do agents get confused?
- **Recovery ability**: Can the agent self-correct or does it death-spiral?
Each scenario gets an **AX Score** (Agent Experience Score), drawing from [Mathias Biilmann's](https://www.linkedin.com/in/mathias-biilmann-christensen-a5a3805/) framework for designing [Agent Experience](https://biilmann.blog/articles/introducing-ax/). Just like school, but for how well your CLI plays with artificial intelligence.
## The Uncomfortable Truth About Developer Tools
Running AgentProbe on popular tools revealed brutal truths:
**Authentication flows** assume human interaction. Multi-step OAuth dances that require browser windows? Agent killer.
**Error messages** assume context humans have but agents don't. "Permission denied" means nothing without knowing *which* permission or *why* it was denied.
**Success states** often rely on visual cues or implicit understanding. Agents need explicit, parseable confirmation.
The real question: do we need better AI agents or better tools?
## The $0.15 Deploy That Changes Everything
Here's the kicker: that chaotic Vercel deployment? **13 turns, 22 messages, $0.15 in Claude credits.**
For a human developer, running `vercel deploy` takes seconds and costs nothing beyond the service itself. For an AI agent, it's a multi-turn negotiation with ambiguous outcomes and real monetary cost.
This isn't sustainable. Not when we're racing toward a world where agents handle routine deployments, testing, and maintenance.
## Why This Matters Now
The competitive advantage is shifting. It's not about having the best AI anymore, everyone will have access to frontier models.
**It's about building tools that agents can actually use.**
AgentProbe reveals the specific friction points.
Fix these, and your tool becomes a force multiplier in the AI-native stack.
## You Can Use It With Claude Code MAX Subscription
Fun update: AgentProbe now works with OAuth tokens from Claude Code MAX subscriptions. Test your tools without agent API costs.
Users need to save their Claude Code MAX OAuth token to a file:
```bash
echo "your-oauth-token" > ~/.agentprobe-token
```
The irony isn't lost on me. I built a tool to test AI agent interactions, and it needs AI agents to run. It's turtles all the way down.
But that's the point. We're building for a world where AI uses our tools as much as humans do. Maybe more.
## The Path Forward
AgentProbe is open source because this problem is bigger than any one tool or company. We need collective intelligence on what makes CLIs agent-friendly.
Every test run teaches us something:
- **Explicit is better than implicit**
- **Structured output beats human-readable prose**
- **Single-step operations outperform multi-step wizards**
- **Deterministic behavior trumps flexible options**
The tools that embrace these principles won't just survive, they'll thrive in the agent economy.
## Start Testing Your Tools
Run AgentProbe and against your CLI without installing it using uvx:
```bash
uvx --from git+https://github.com/nibzard/agentprobe.git agentprobe test vercel --scenario deploy
```
**AgentProbe is currently in early development** and needs help from the community. Found issues? Have ideas? [Contribute on GitHub](https://github.com/nibzard/agentprobe) to help build better AI-native tools.
Share your results on X (formerly Twitter) and tag [@nibzard](https://x.com/nibzard). The more data we collect, the better we understand how to build for both human and artificial users.
Because here's the thing: **we're not choosing between human-friendly and agent-friendly anymore.**
The winners will master both.
---
*The future isn't about better agents or better CLIs. It's about tools that communicate fluently.*