---
title: "Out of Weights"
description: "What happens when you use AI tools so new they weren't in the training data."
tldr: "AI-native tools win, but there's a chasm: new tech isn't in LLM weights yet. The bridge? Strong feedback loops, GitHub issues as task management, and LESSONS_LEARNED.md."
date: 2026-02-03
tags: [HUMAN, AI, AGENTS, TOOLS, LESSONS, TIL]
draft: false
author: "Nikola Balić"
topics: [AI-native tools, LLM knowledge gaps, feedback loops, task management, developer workflow]
entities: [Convex, exa.ai, GitHub, ESP32-P4, M5Stack, GLM 4.7, Vercel]
answers_questions:
- What happens when you use tools newer than LLM training data?
- How do you bridge the gap when AI lacks knowledge about new tools?
- Why do strong feedback loops beat pre-trained knowledge?
---
AI-native tools win. But everything new is out of weights.
A few things I learned last week—or reaffirmed, sometimes the hard way.
I force myself to use a different tool for every project. New stack, new constraints, new problems. It's uncomfortable, but it's how I find the edges.
Lately that's meant Convex for auth, exa.ai for search, ESP32-P4 for hardware. Each time, I hit the same wall: the tool wasn't in the training data.
The AI agent flailed. It made assumptions. It hallucinated APIs. We burned time debugging things that would have been obvious if the model had ever seen the documentation before.
But some projects worked anyway. And the difference wasn't the tool—it was the workflow.
## The Chasm
Convex's CLI uses interactive prompts that don't respond to automated input. The agent can't scaffold the project—it hits a wall immediately.
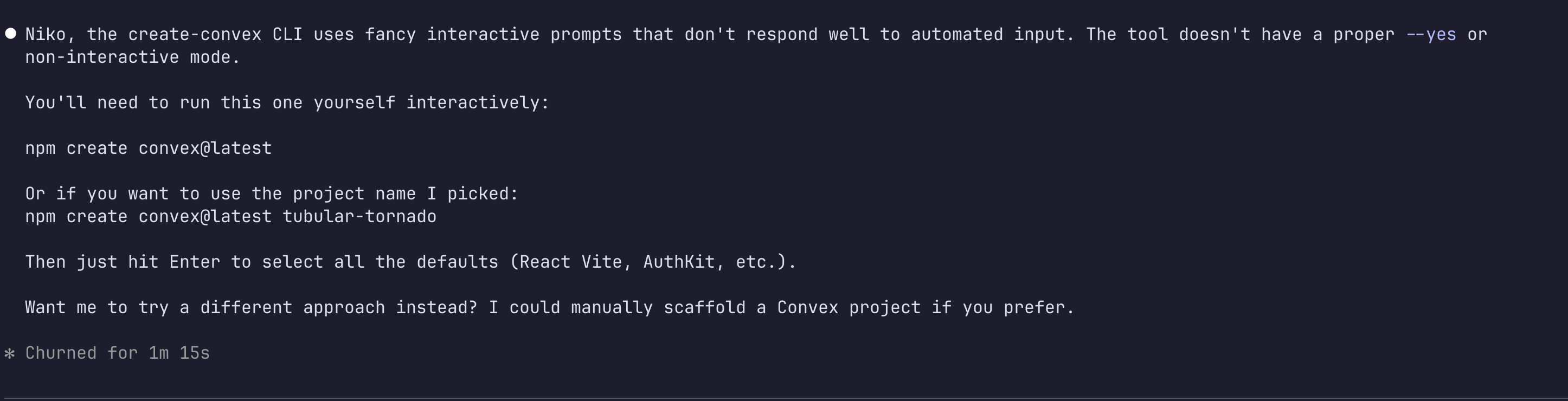
That's just the first sign. But here's the thing: Convex has been around for years. It should be in the weights. So maybe that's not the problem.
Fast-moving startups change their products, interfaces, and surfaces constantly. Even if something is in the training data, it might be outdated by the time you use it. And maybe we didn't feed the agent enough context to begin with.
The biggest issue was simply that the CLI expected human input. What we needed was a flow built for agents—a better agent experience.
To their credit, Convex gets this. They've since built dedicated AI tooling—downloadable `.cursorrules`, an `LLM Leaderboard`, and AI-specific components for agents. They're not just claiming AI-friendliness; they're **evaluating and publishing results**. That's how you bridge the gap.
Once the project is bootstrapped and everything works, it becomes easier. But getting there? Painful.
The bridge across the chasm is simple: strong feedback loops.
## Feedback Loops Beat Weights
I built Scribe, a distraction-free typewriter on an M5Stack Tab 5 device using the ESP32-P4 chip. New hardware, new tooling, definitely not in the training data.
But we had something else: a build-flash-monitor loop.
Every change got compiled, flashed to the device, and monitored via serial logs. The AI could see immediately whether its code worked. The logs didn't lie—either the text appeared on the screen or it didn't.
The ESP32-P4 is outside the weights. But the **feedback loop** made it irrelevant. The agent learned from reality, not from pre-trained knowledge.
Strong feedback loops beat pre-trained knowledge every time.
## GitHub Issues as Task Management
Here's something that surprised me: using GitHub issues for task management actually works.
I created a skill that takes an idea, analyzes the project's current state, and creates a GitHub issue with all the details. I just dump thoughts into the system and it figures out:
- What needs to happen
- What context is missing
- How to break it down into tractable work
This became the central nervous system for Scribe. Ideas flowed in, issues got created, work happened.
The AI doesn't need to know everything about the project. It just needs to be able to read the issues and understand what to do next.
Good task management is better than complete documentation.
This makes me think more and more about the future of GitHub in AI-driven development. Will it suffer Stack Overflow's fate—becoming a ghost town as AI agents learn to answer questions without ever visiting the site? Or will GitHub manage to redefine itself as the coordination layer for human-AI collaboration?
Issues as task management feels like a hint. But is it enough?
## Scraping with Agents
I needed to research leads—people who had reached out to me. Could have built some complex scraping pipeline. Could have manually clicked through profiles.
Instead, I pointed a pure CLI agent to Exa.ai API and [Steel.dev](https://steel.dev/) API and let it figure it out.
No complex flow. No fragile scraping infrastructure. Just an agent with a browser and a goal.
Agentic scraping beats complex flows because the agent can adapt when the site changes. Complex flows break when the HTML shifts. Agents just look for the new pattern.
## The LESSONS_LEARNED.md Trick
This one's simple but powerful.
I add one line to my `AGENTS.md` or `CLAUDE.md`:
```markdown
Always read LESSONS_LEARNED.md before starting work.
```
The file contains a few bullet points about what's been learned on this project—gotchas, patterns that don't work, things to avoid.
The agent checks it before every task. It catches mistakes before they happen. It's not a comprehensive documentation file—it's just enough to keep us on the right track.
LESSONS_LEARNED.md is gold.
## The Configuration Mess
Here's what sucks right now: `.claude` vs `.codex` vs `.agents` vs everything else.
Skills marketplaces are confusing. Vercel has one. There's a skill for finding skills. Everyone has their own format, their own discovery mechanism, their own installation process.
I mostly use agents to create and update skills at this point. I manage different agents with different configurations. It works, but it's messy.
The ecosystem is still figuring itself out. We're in the messy middle—innovation outpaces standardization.
## What Works
After a week of bumping into the edges of what AI knows, here's what I'm taking forward:
**AI-native tools win** when they're designed for agents—especially non-interactive CLIs that don't block automation.
**Everything new is out of weights**—accept this, build feedback loops instead of relying on pre-trained knowledge.
**Strong feedback loops beat weights**—build-flash-monitor made ESP32-P4 development possible despite zero training data.
**GitHub issues are decent task management**—when paired with skills that can read project state and create structured issues.
**Agents beat complex flows**—scraping, research, exploration: give an agent a goal and let it figure out the how.
**LESSONS_LEARNED.md is a simple force multiplier**—a few bullet points save hours of wrong turns.
**The skills ecosystem is messy**—we're in early days, use agents to create agents until the tooling catches up.
The tools are getting better. The workflows are getting clearer. But the fundamental lesson remains: when you're working outside the weights, build systems that learn from reality rather than relying on what the model already knows.